

构建真正连接物理世界的世界模型:跨维新进展-从 3D 可动物体生成到可执行视频世界模型
要真正解决具身智能(Embodied AI)在现实世界中的长期命题,仅仅让模型“看懂”像素是不够的。跨维智能团队始终认为:要真正解决这一痛点,系统必须与真实世界的 3D 物理建立起深层的关联。即模型理解世界的结构、物理规律与动态变化,并在其中做出可靠的决策与执行。
过去几年,基于视频生成的世界模型技术取得了显著进展。但对于机器人而言,这些能力只是起点——一个只能生成或预测二维视觉序列的系统,距离真正能够在物理世界中稳定操作还相差甚远。
沿着这一核心理念,我们团队一直在持续演进一条更基础、也更长线的技术脉络:面向真实交互场景构建一个完整的世界模型 World Models of Generative Simulation (GS-World),即物理合理的、可交互的、三维原生的世界模型。而在这条通过 GS-World 理念以及开源引擎 EmbodiChain 所驱动的链路上,我们近期又推出了两项极具代表性的最新工作:
PAct:解决了“物理世界的基础单元如何高效生成”的问题,实现从单图快速生成结构化、能运动的铰链式 3D 对象。
EVA:解决了“世界模型如何真正指导机器人”的问题,通过强化学习将视频生成分布主动拉回到机器人可执行的物理流形上。
技术主线概览
如上近期推出的多个研究工作并非孤立的研究节点,而是共同指向同一个目标:让世界模型不只是"能够想象未来",更是"能够赋能机器人在真实三维物理世界中做得出来"。
以下,我们将分别介绍这两项最新工作的核心思路与实验进展,并在最后回到整体框架,说明它们如何共同构成我们通向具身世界建模的技术基石。
基础对象层:PAct——让复杂物体(铰链式物体)生成更快、更准、更可控
1.1
为什么先从"可动物体"入手?
在任何具身世界模型中,铰链式物体(articulated objects) 都是最核心、也最常见的基本单元。柜门会转动、抽屉会滑出、微波炉门可以开合——这些带有活动结构的对象广泛存在于真实世界的操作场景中。
只有先把这些对象建模成可分解、可运动、可交互的结构化实体,后续更高层的图建模、动态推演和交互预测才有可靠的基础。仅仅生成一个"静态3D模型"远远不够——还必须同时恢复其部件结构、关节类型、转动轴、活动范围等关键信息。
然而,这类高质量可动3D资产的构建一直很难规模化、自动化地生成。
一类方法依赖逐实例优化或蒸馏:虽然结果可能较准确,但往往需要每个物体花上几十分钟甚至数小时;
另一类方法依赖模板库或部件检索:速度更快,却常常难以真正匹配输入图像中的具体结构和外观,生成结果"像个柜子",却未必是"这个柜子"。
1.2
PAct 的核心思路:以部件为中心的联合生成

上图展示了给定单张图像,PAct 可以批量生成机械臂可操作的可铰接式三维物体
论文标题:PAct: Part-Decomposed Single-View Articulated Object Generation
代码链接:https://github.com/PAct-project/PAct(已开源)
PAct 的核心思想可以概括为一句话:不要把铰链式物体当成一个整体去"猜",而要把它看成一组具有语义和运动关系的可动部件,进行以部件为中心的生成。
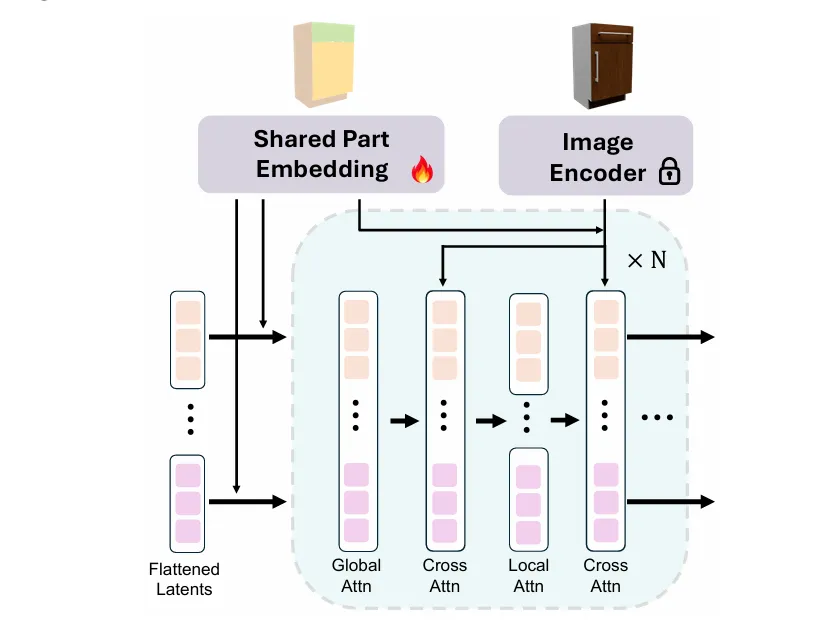
在表示方式上,PAct 将一个铰链式物体建模为一组可动部件,每个部件由 latent token 表示,并显式加入部件身份信息以区分不同部件。在单张输入图像的条件下,模型不仅要生成物体的3D几何和纹理,还要同时生成运动结构。
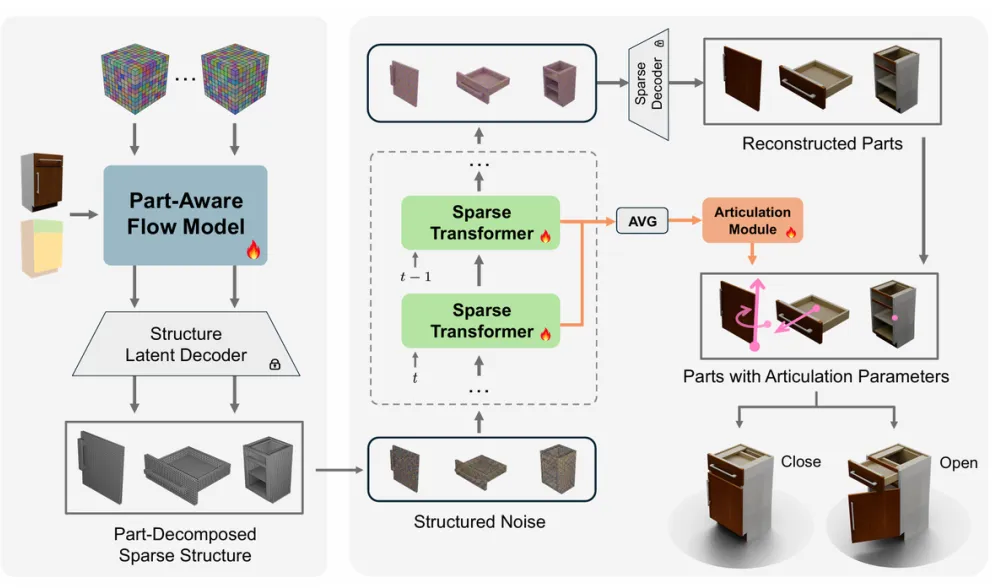
PAct 采用两阶段流程实现这一目标:
第一阶段:预测部件分解后的稀疏结构
模型先根据单张图像,利用部件感知的流匹配(Part-aware Flow Model) 预测所有组成部件的粗粒度结构——先回答"这个物体有哪些部件、它们怎么组成整体"。这一阶段通过显式的部件条件控制(part-aware conditioning),让结构生成不再是黑盒式整体预测,而是带有明确部件先验。
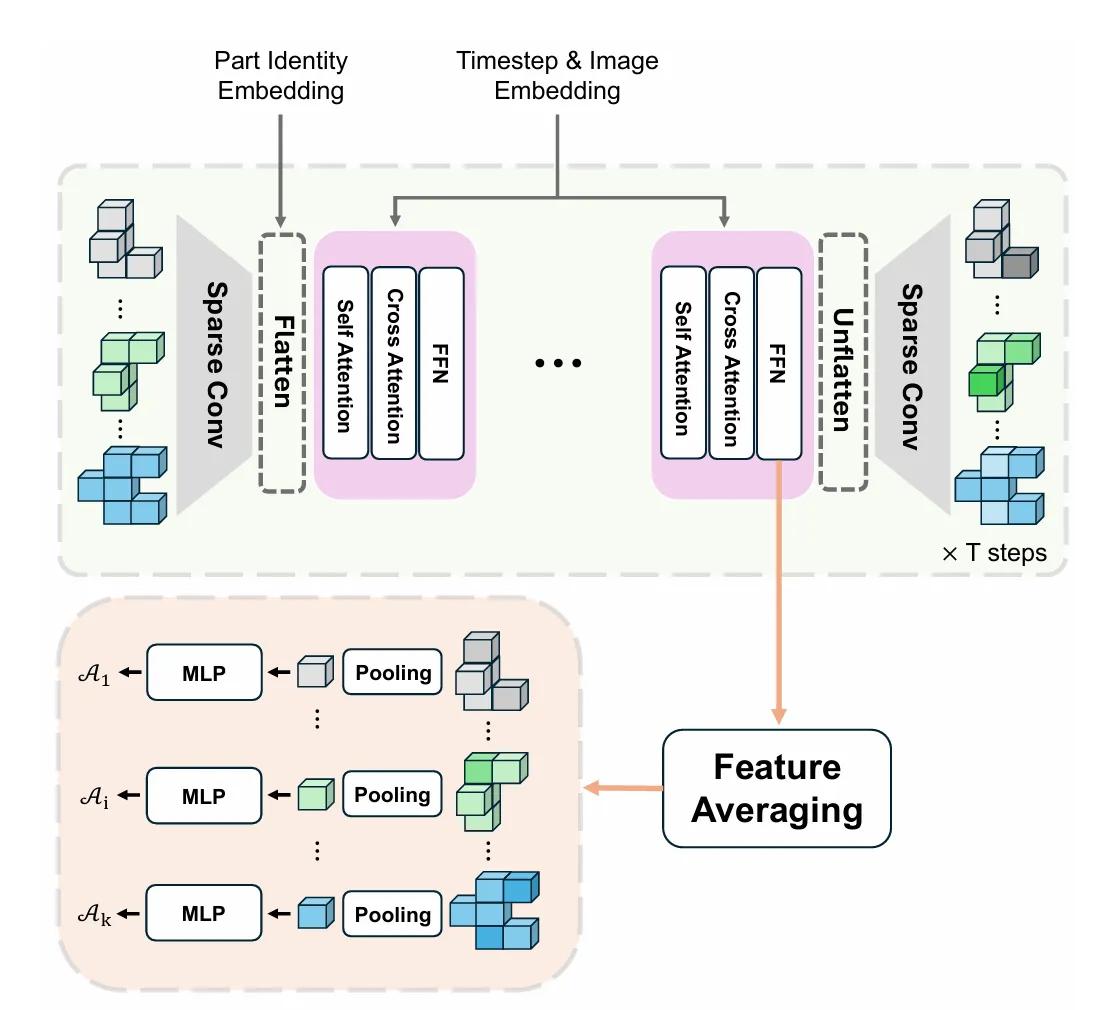
第二阶段:生成精细部件表示,并回归动态信息
在得到部件结构后,PAct 再通过稀疏 Transformer 的去噪过程,将粗粒度结构进一步细化为高保真的3D部件几何与外观;同时,多步去噪得到的特征被聚合用于生成每个部件的动态信息(运动轴、关节类型、活动范围等)。
换句话说,PAct 不是"先生成一个3D物体,再想办法给它加骨架",而是一开始就把部件结构、几何外观、运动的动态过程放进统一框架中联合考虑。
1.3
PAct 的高可用性:从“长得像”到“物理可信”与高效推理
在 PartNet-Mobility 等权威数据集上,PAct 不仅在几何误差和 Chamfer Distance 上超越了现有的代表性方法(如 Articulate-Anything、PhysX-3D 等),更重要的是,它还原了真实的部件边界和可信的关节参数。
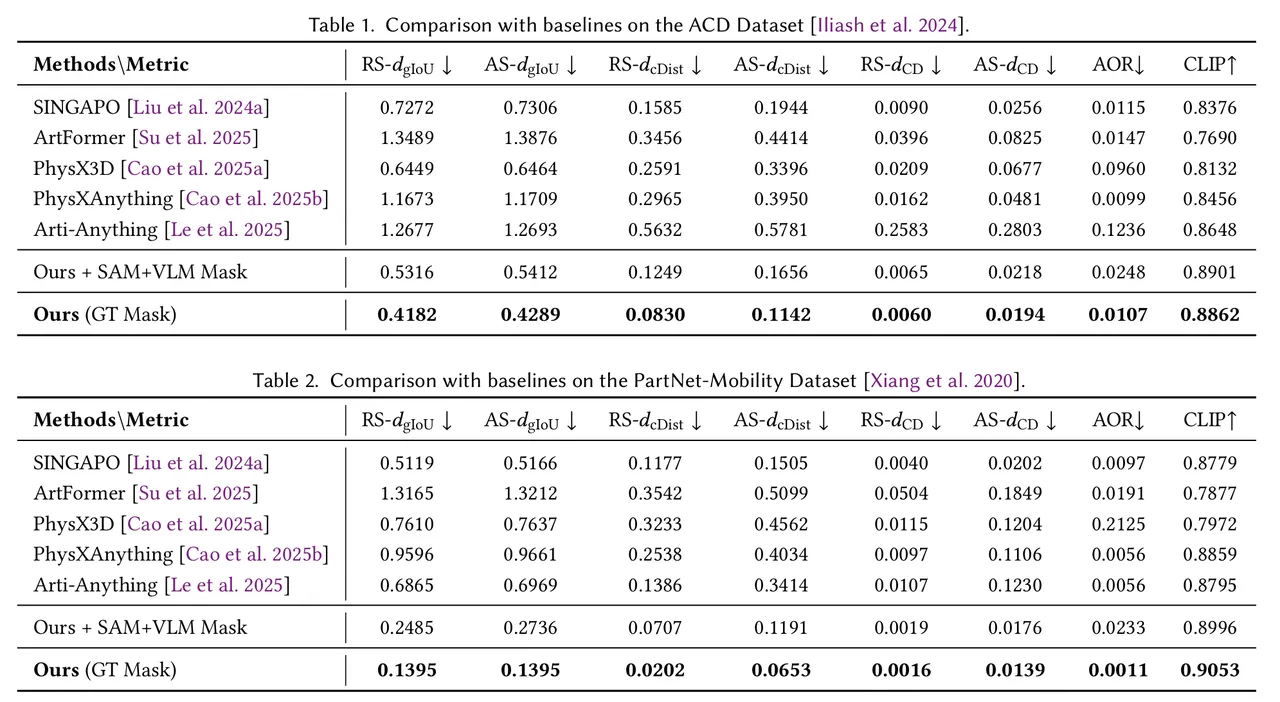
更令工业界兴奋的是它的高效性与可控性:
极致推理速度:单样本推理时间压缩至约 15 秒,属于当前路线中的绝对第一梯队,非常适合大规模仿真数据合成

真实世界泛化:面对充满光照和材质噪声的 In-the-wild 真实图像(如真实的微波炉、书桌),依然展现出强大的迁移能力。
掩码级可控:同一张外观图,用户可以通过二维掩码(Mask)显式指定它是“双门结构”还是“两扇门+两个抽屉”的结构,打破了传统生成的“盲盒”体验,可控性大大提升。
PAct 的可扩展性:从运动结构到完整物理属性
值得一提的是,PAct 的框架并不局限于生成关节参数和运动结构。由于它采用的是以部件为核心的结构化表示,因此也非常容易进一步扩展到物理属性生成,例如质量、材质、摩擦、刚度以及其他与交互和动力学相关的属性。
也就是说,PAct 不仅能够回答"这个物体怎么动",还有潜力进一步回答"这个物体在物理世界里会怎样运动、怎样响应作用力"。
这使得该方法能够较为轻松地扩展到我们更通用的世界模型表示框架中,成为3D物理世界模型里的基础对象层。对象不再只是静态几何或运动骨架,而是具备结构、运动和物理属性的完整实体,从而能够被进一步组织进更大尺度的场景图和动态世界模型之中。
执行对齐层:EVA——用强化学习让视频世界模型在机器人上真正"动"起来
2.1
视频世界模型的关键瓶颈:可执行性鸿沟
如果说 PAct 打造了物理世界的可交互资产,那么 EVA (Executable Video Alignment) 框架则致力于让机器人的“大脑”真正掌握物理世界的交互规律。
现在很多世界模型,在脑海中“想象”未来视频时非常逼真,但由于它们并不真正理解机器人的本体结构、关节约束和运动学规律,生成的轨迹往往存在机械臂局部形变、关节穿模和时序跳变。这种在视觉上难以察觉的微小瑕疵,经过逆动力学解码后,会酿成灾难性的执行错乱。这就是这类路线令人头疼的“可执行性鸿沟” (Executability Gap)。
2.2
EVA 框架:以逆动力学奖励驱动强化学习对齐
论文标题:EVA: Aligning Video World Models with Executable Robot Actions via Inverse Dynamics Rewards
EVA 的核心思想直接而有力:既然机器人最终需要的是可执行的动作序列,那么视频生成模型的训练目标就不应只由视觉质量决定,而应进一步引入来自动作空间的约束。
具体实现:EVA 首先训练一个逆动力学模型(IDM),让它能够根据视频中的局部时序变化恢复出机器人动作;随后,将这个 IDM 扩展作为奖励模型,用于评估视频生成结果对应的动作序列是否平滑、合理、符合机器人本体约束。
训练过程分为两个阶段:
监督微调阶段:模型回答——这段视频看起来真实吗?是否符合任务语义?
强化学习对齐阶段:模型进一步回答——这段视频如果被翻译成动作,机器人到底能不能执行?它对应的动作轨迹是否平滑?是否违反速度、加速度等本体约束?是否会产生突兀跳变或不稳定控制?
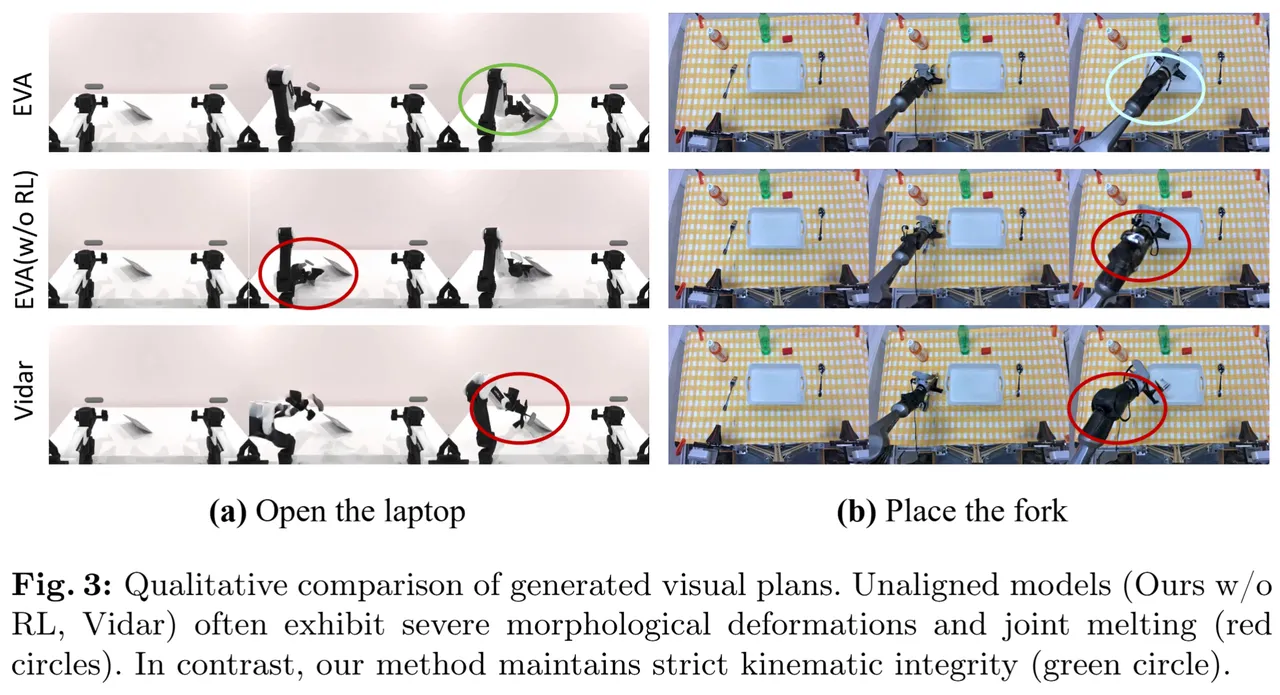 在奖励设计中,研究团队显式引入了动作速度变化、加速度平滑性以及更高阶的 jerk 正则项,同时对超过机器人本体限制的异常动作进行惩罚。
在奖励设计中,研究团队显式引入了动作速度变化、加速度平滑性以及更高阶的 jerk 正则项,同时对超过机器人本体限制的异常动作进行惩罚。
从本质上看,EVA 并不是简单地"修补视频中的瑕疵",而是在将视频生成分布主动拉回到机器人可行运动流形之上。
2.3
深入大考:无可争议的跨越式提升
视觉规划质量:经过 RL 对齐的 EVA 模型在"运动学合理性"(Kinematic plausibility)上相比未对齐基线模型提升了 20.9%,Perfect Execution 达到 83.8%。这说明 EVA 优化的不只是"画面是否自然",而是在减少机械臂形变、关节歧义和时序跳变等对执行极其重要的结构性伪影。
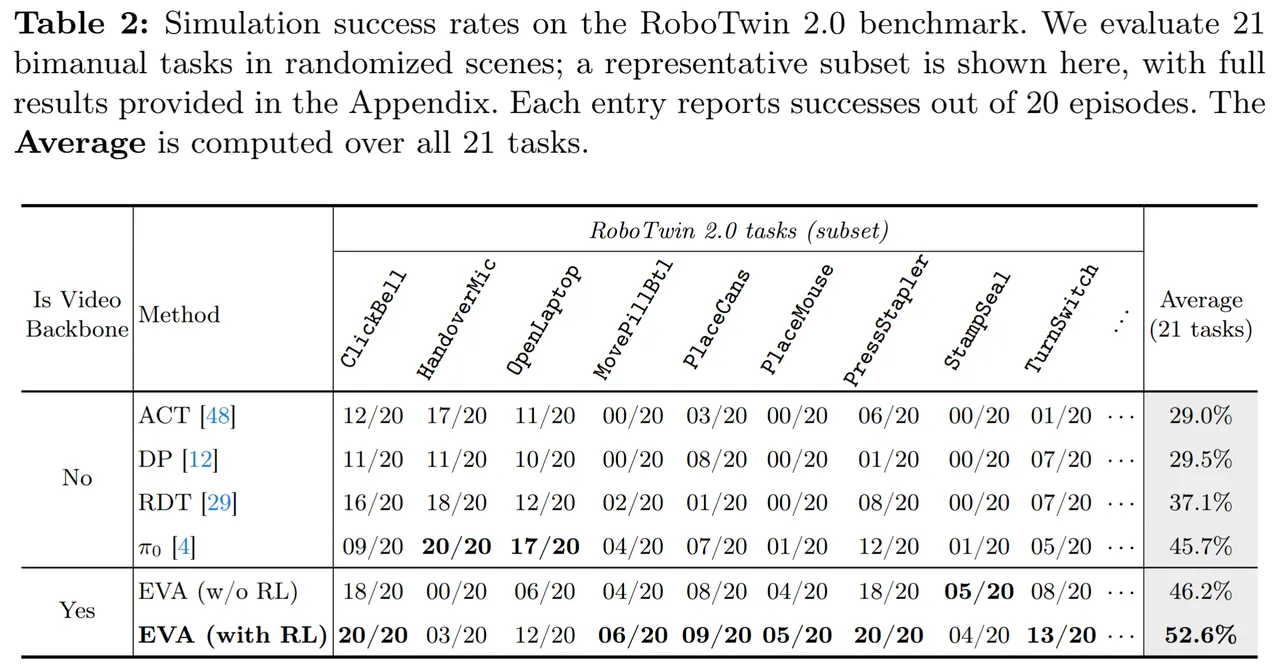
仿真任务成功率(RoboTwin 2.0):研究团队选择 RoboTwin 2.0 作为核心评测基准。选择 RoboTwin 的原因在于:它面向双臂操作任务,任务类型丰富、场景随机性强,已逐渐成为检验 VLA 方法与具身世界模型方法泛化能力和真实执行潜力的重要公开基准,在这一平台上的结果具有较强的说服力。
在 21 个双臂任务的系统评测中,评测方式并非只比较生成视频"看起来好不好",而是将生成视频交给 IDM 解码为动作序列,再真正送入控制系统执行并统计成功率——考察的是"视频世界模型生成的未来,究竟能不能被机器人真正做出来"。
结果显示,EVA(with RL)将平均成功率提升至 52.6%,不仅明显超过未对齐版本,也整体优于多种代表性 VLA 方法和机器人基础模型基线。代表性任务表现如下:
真实机器人部署:
研究团队进一步在真实双臂机器人平台上进行了部署测试,结果显示 EVA 的优势稳定延伸到了真实部署阶段:
Seen tasks:EVA(with RL)达到 64.0%,明显高于 ACT、$pi_0$、Vidar 和 GE-Act 等代表性基线;
OOD tasks(5个全新任务):EVA(with RL)将平均成功率提升至 60.0%,展现出更强的新任务适应能力和跨场景泛化能力。
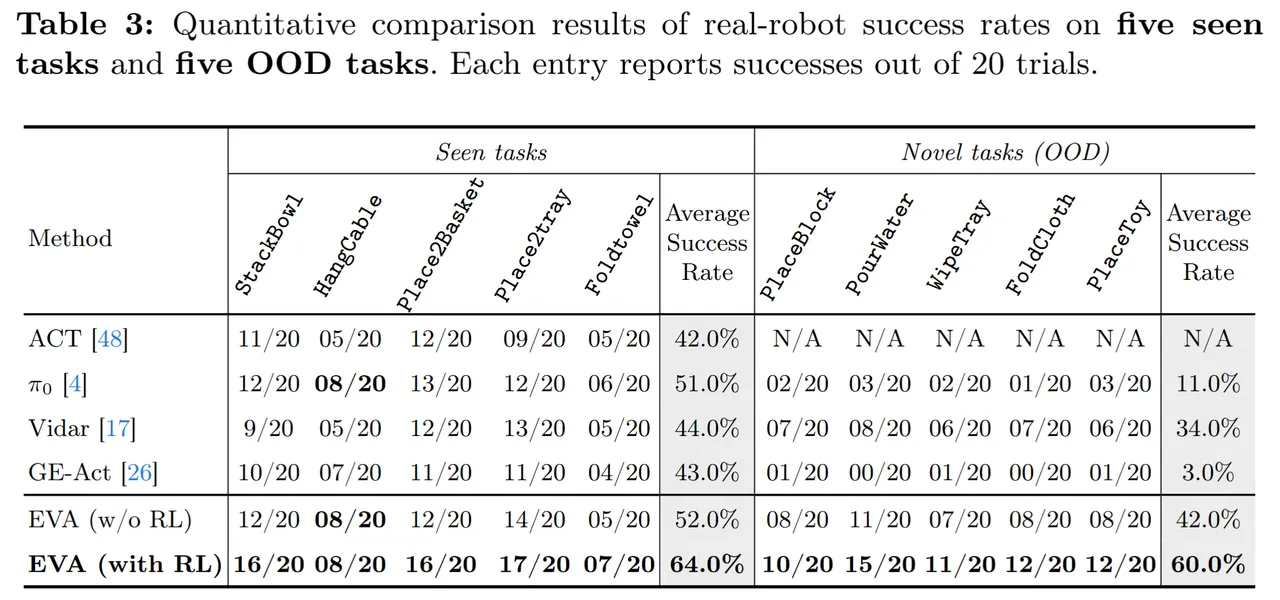
这一结果尤为值得关注:与仿真环境相比,EVA 在真实机器人部署中的优势反而更加明显,gap 进一步拉大。这说明 EVA 所弥合的可执行性鸿沟,在真实物理世界中的影响比在仿真中更为突出——越是接近真实部署,对执行合理性的要求就越高,而 EVA 的对齐机制正是在这个维度上发挥了关键作用。
这些数据背后对应的,正是 EVA 的核心判断:对于具身世界模型来说,真正决定落地价值的,不只是"能不能生成未来",而是"生成出来的未来,能不能被机器人可靠地执行"。
从"会生成"到"会执行",迈向真正的具身世界建模
上述两项工作并非孤立存在,而是建立在我们团队此前提出的两个核心框架之上:GS-World(World Models of Generative Simulation)致力于为具身系统提供一个可生成、可模拟、可演化的具有准确三维物理特性的世界模型表示。EmbodiChain 则作为面向具身智能的全套工具链,连接场景生成、数据合成、模型训练和真机部署,构成整个技术链路的系统性集成平台。
当这两种能力——可动对象的结构化生成PAct与执行层面的物理对齐EVA——被进一步放入 GS-World 与 EmbodiChain 所构建的更大框架中,被统一组织进一个会演化、可推演、符合物理规律的3D世界模型时,我们距离真正意义上的 Embodied World Modeling,也就更近了一步。
跨维智能正在一步步将世界模型拉回三维物理的本源。打破可执行性鸿沟,让具身智能真正在物理世界落地生根,这正是我们持之以恒的愿景与路径。

